

AMD CPU Topology - Rome + Milan


Last time we covered Intel CPU inter-core interconnect topologies from the Cooperlake and Ice Lake server products. Next up, we’re going to cover the last two generations of AMD server CPUs, Rome + Milan.
Core Count Scaling
As the size of a physical CPU die increases, yield of working dies from a wafer decreases, and cost per processor rapidly increases. To pursue higher core counts, a couple approaches are possible.
One is to make each core smaller to pack the same number of cores onto the same physical footprint on a silicon die. This is the approach taken by GPUs, with the latest nVidia H100 GPU packing upwards of 18000 simple cores. The drawback is such small and simple cores must typically forgo much of the functionality required to drive high per-core throughput on general purpose server workloads. Its not realistic to fit a full out-of-order execution pipeline, large caches, and other circuitry in such a small footprint. For general purpose CPUs running branchy, complex workloads, lack of those features is a non-starter.
Another approach is to lash together multiple smaller dies (so called chiplets) onto a single physical package (PCB) or connected through a tightly coupled silicon interposer. Each chiplet is smaller, and thus is easier and cheaper to produce. The challenge is how to integrate multiple chiplets into a single package/PCB with sufficient performance to appear like a single CPU to applications and at a low enough price to be economical. This is the approach that AMD took to beat Intel in the core count race.
CCXs + CCDs
Compared to the monolithic dies Intel has used up to the Ice Lake generation of CPUs, AMD took a more aggressive tact, adopting chiplet technology much more rapidly than Intel did.
AMDs chiplet implementation is built around CCDs (Core Complex Dies) and CCXs (Core Complex). Each CCX is comprised of a set of CPU cores sharing a common L3 cache block. In Rome, each of those CCDs sports a pair of 4 core CCXs, while in Milan each CCD has a single CCX with 8 rather than 4 cores. Across both generations, each CCD has up to 8 cores.

Here we see a photo of a Rome CPU package. The smaller dies around the outside of the package are the CCDs. The middle rectangular silicon die is the IO die, through which the various CCDs are connected to one another through AMD’s Infinity Fabric interconnect.
Milan follows the same general pattern as Rome with one significant difference. Unlike Rome with two 4 core CCXs on each CCD, Milan instead opts to have a single 8 core CCX on each CCD. This improves upon a major weakness of Rome. We’ll come back to this when we look at the RTT latency between CPU cores.
Rome
First up is an AMD Rome based system. This is a AWS c5a.metal instance running a pair of AMD EPYC 7R32 48-core CPUs. The shot below shows the inter-core latencies across cores on the same CPU package.
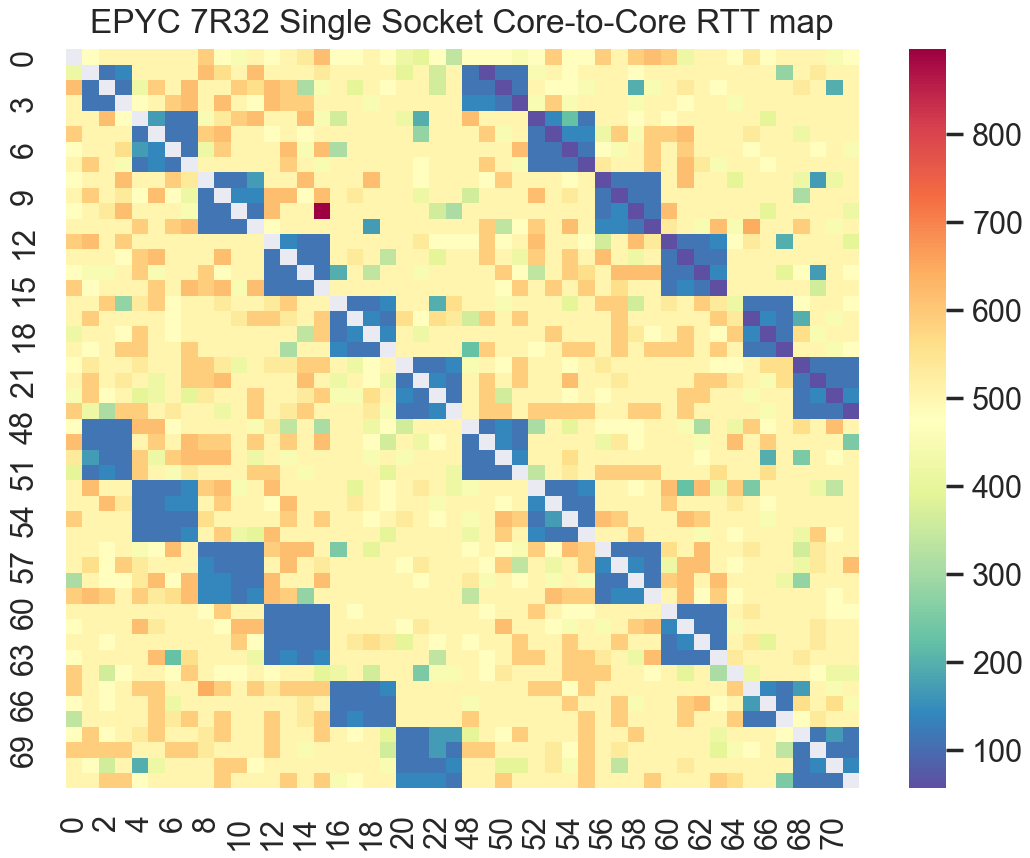
Right away, the variance in RTT between cores on different CCXs stands out. In fact, comparing this with RTTs for monolithic Intel dies in a NUMA configuration, Rome almost appears like a set of 6 different NUMA nodes together. In fact, AMD offers a so-called NPS4 (Nodes Per-Socket - 4) mode that exposes each CCD as a separate NUMA node to the operating system.
We can visibly observe the individual CCXs as the low latency blue blocks. From the size of the blocks in the latency map, we can even see how each CCX is 4 cores/8 threads. Each of the 4 core (8 thread) CCXs have very low RTT internally, while a fairly large penalty is paid to communicate with cores on other CCXs. Interestingly, the inter CCX communication penalty is paid even when communicating with cores located on the other CCX on the same CCD. This is because inter-core traffic between any pair of CCXs must traverse the Infinity Fabric from the CCX → IO die → CCX, even if the CCXs are on the same physical die.
In practice, this is one of Rome’s biggest achilles heels. For workloads which frequently exchange data between more than a handful of threads, this high inter-core latency is a problem. For small groups of threads, pinning those threads to the cores in a single CCX will solve the problem and keep communication costs low. But with 4 core, 8 thread CCXs, its difficult to keep a meaningfully large workload fully pinned to a single CCX on Rome, any workload with more than 8 concurrently running threads must spill across multiple CCXs and take a huge latency hit. Hence many intensive highly concurrent workloads did not scale well on Rome, hindering Rome’s adoption for certain workloads.
AMD was well aware of this flaw, and later generations started to address it, as we’ll see with Milan.
Milan
Next up is an AMD Milan based system. This is an AWS c6a.metal host running a pair of AMD EPYC 7R13 48-core CPUs.
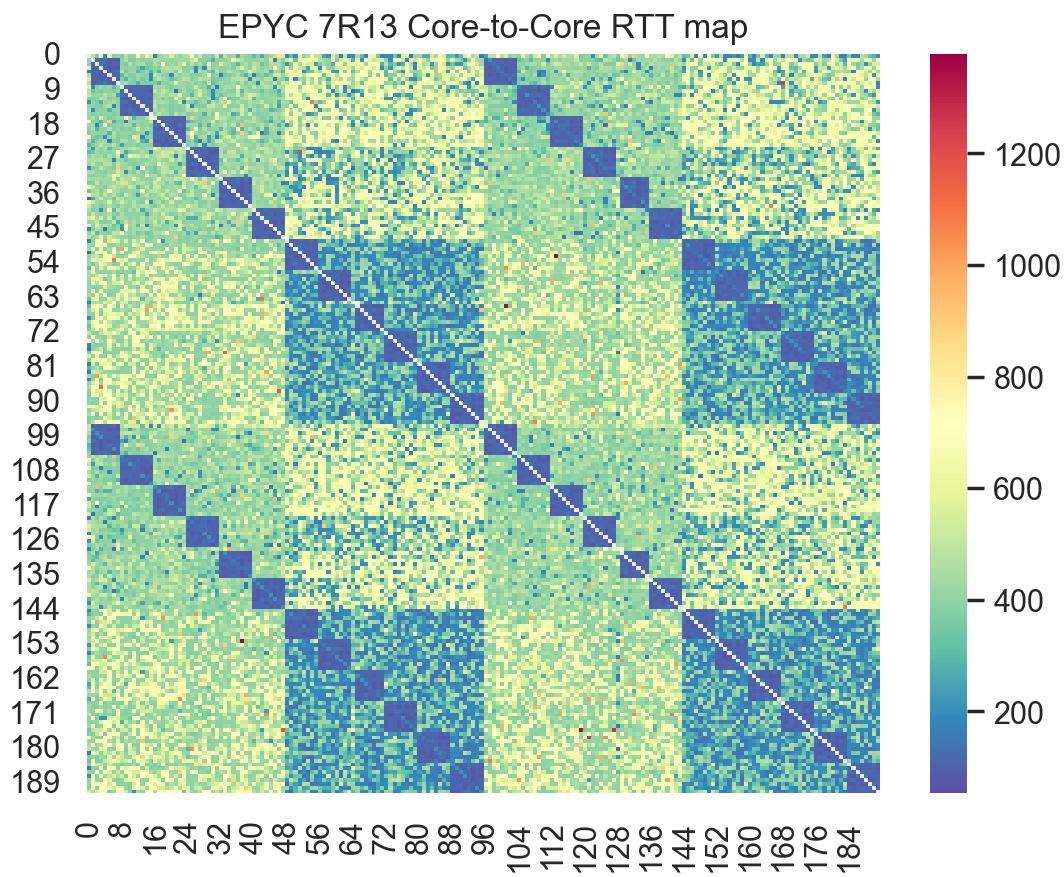
Taking a look first at the full latency map across all cores in the system, we observe multiple levels of latency across the system. The first level is across NUMA nodes, which is visible as the largest colored blocks. The next level is the small blue blocks running across the diagonals. Each of those deep blue blocks is a single CCD/CCX.
And finally, as can be seen below, the pair of faint light blue lines on the diagonal spanning the upper right and lower left quadrants are the inter-thread RTTs between SMT threads on the same core sharing an L1 cache.
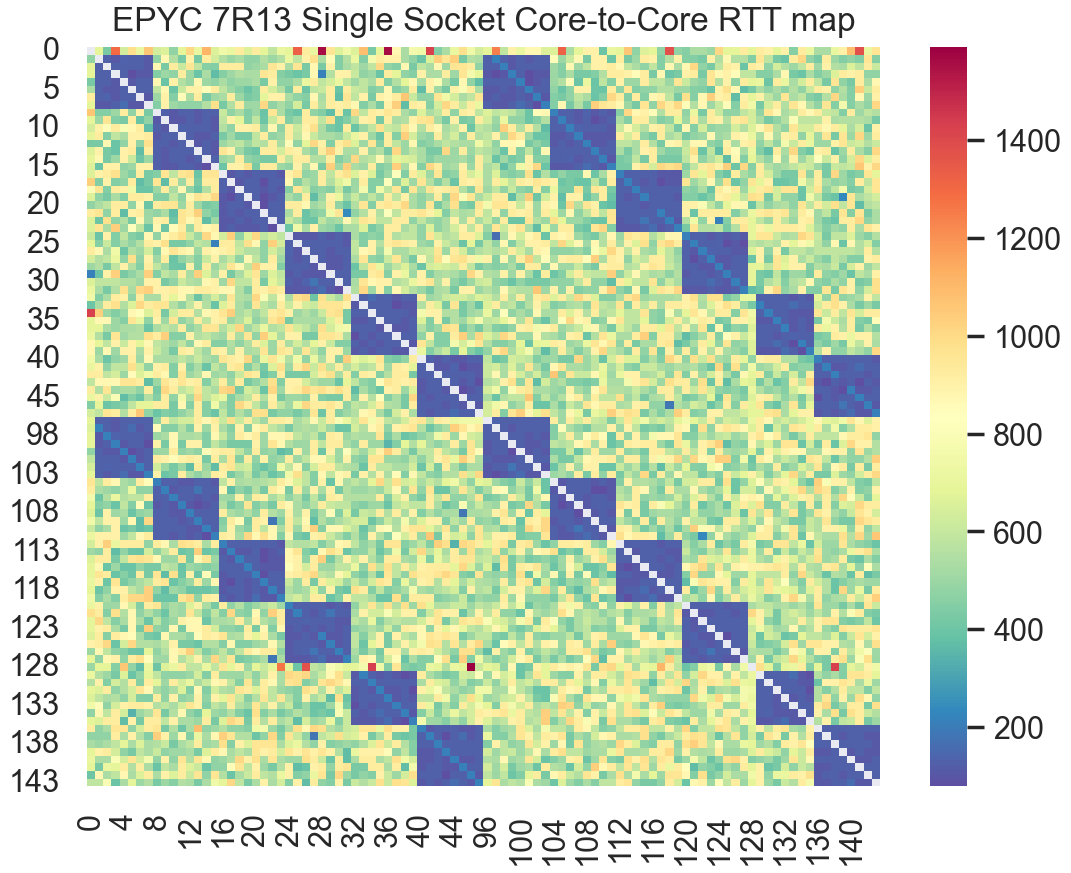
Taking a close look at the single socket inter core RTT shows the larger CCXs in Milan vs. Rome. In Rome, each CCX was only 4 cores/8 threads. In the single socket latency map above, we clearly see the larger 8 core/16 thread CCXs/CCDs. Compared to Rome, Milan’s larger unified CCDs/CCXs enable pinning larger workloads to a single CCD/CCX to avoid the penalty for communicating across CCD boundaries through the Infinity Fabric interconnect. AMD has also optimized the cost of communicating between CCXs when it is necessary. The result is better scaling for tightly coupled parallel workloads.
Conclusions + Next Up
Looking at AMD, their advanced chiplet packaging enables their EPYC server lineup to scale to much higher core counts per socket than Intel, but this does come at a cost. While Intel CPUs have flat latency profiles across cores in the same die, the same is not true with AMD. Kernel schedulers and even application developers must be mindful to carefully consider locality when assigning threads to cores. The latency difference between CPU cores in different CCXs is non-trivial. And while less extreme than the cost of a full NUMA hop, the impact is still measurable in practice.
Up until recently, Intel has stuck with monolithic CPU dies. However, with the latest Sapphire Rapids (SPR) CPUs, Intel has hopped on the chiplet bandwagon. Intel’s chiplet implementation is more tightly integrated than AMDs, leveraging a new Embedded Multi-Die Interconnect Bridge using lightweight silicon interposers. I hope to perform some similar measurements on a Sapphire Rapids CPU and determine how close SPR performs compared to earlier Intel monolithic dies. How soon that happens will depend on when AWS grants me preview access to one of their Sapphire Rapid’s based R7iz EC2 instances. When that happens, you’ll hear about it here soon…
Excellent post!